▸OmniVoice Studio
liveCinematic audio dubbing, cloning & voice generation
OmniVoice Studio
The open-source ElevenLabs alternative.
Voice cloning · Voice design · Video dubbing — 646 languages, runs 100% locally, forever free.



Download · Features · Quickstart · Why Open Source? · Roadmap
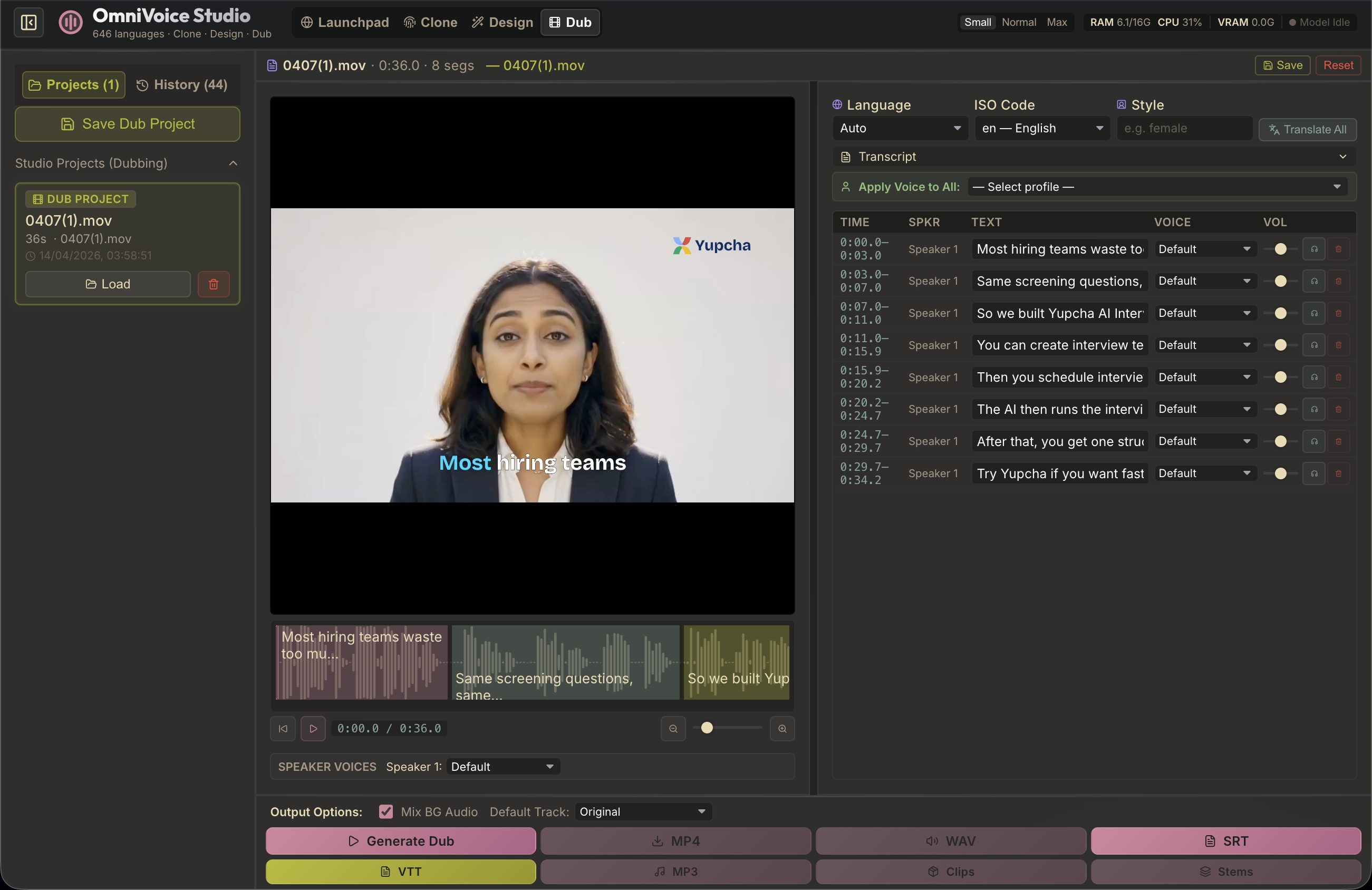
Launchpad — Voice Clone · Voice Design · Video Dubbing, all in one place.
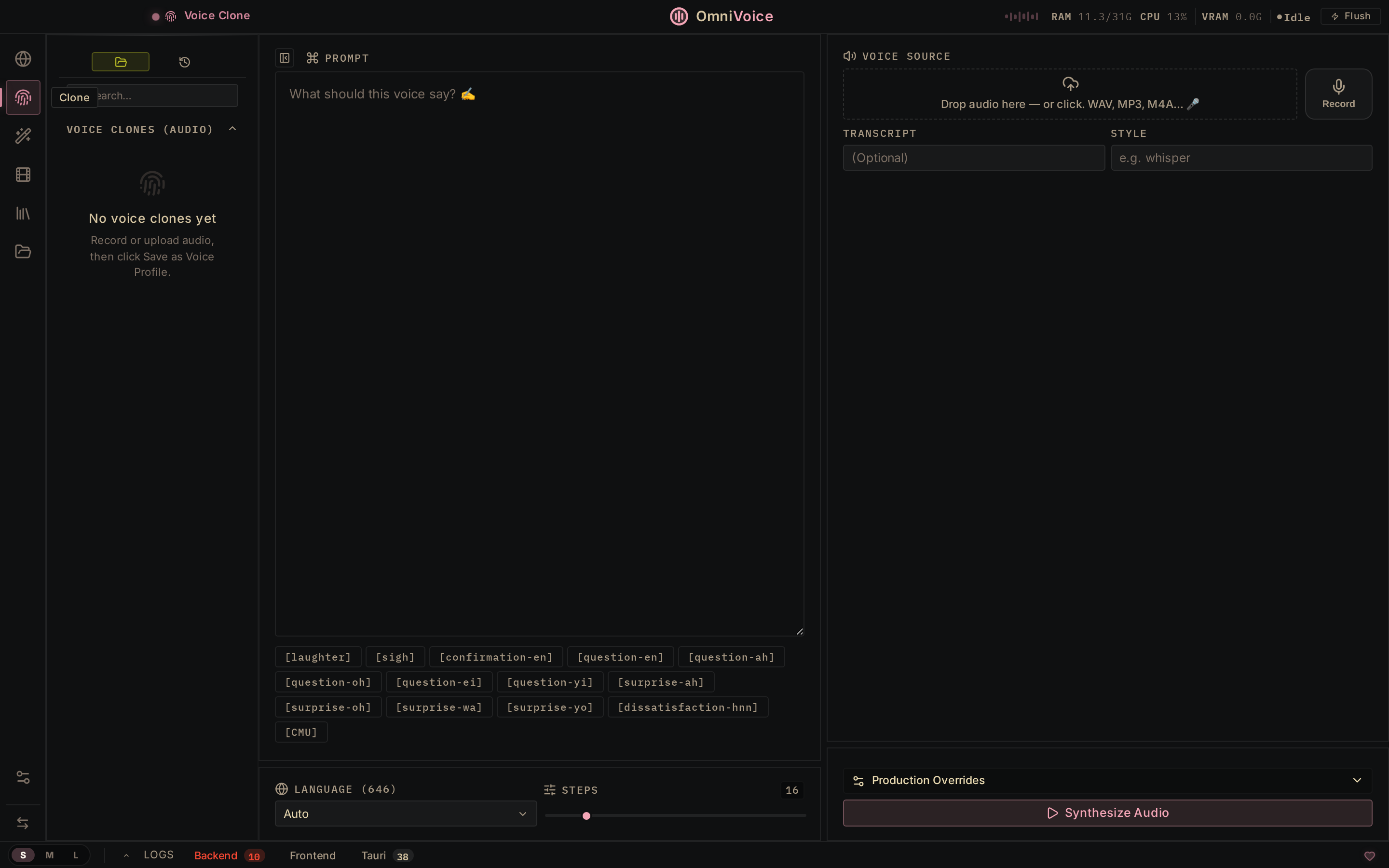
Voice Clone Drop a 3-second clip → mirror any voice. 646 languages, zero-shot. |
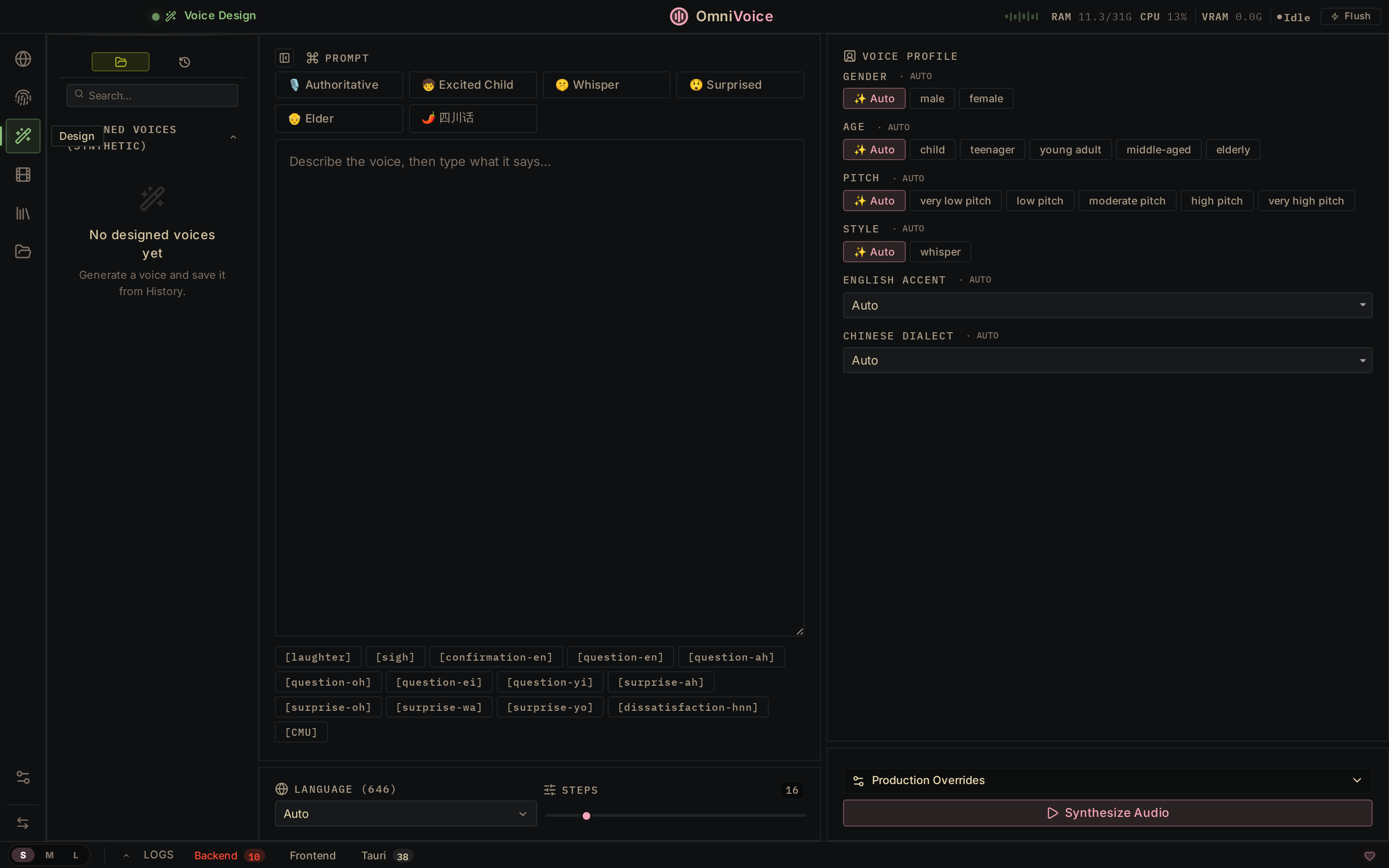
Voice Design Build new voices from scratch — gender, age, accent, pitch, style. |
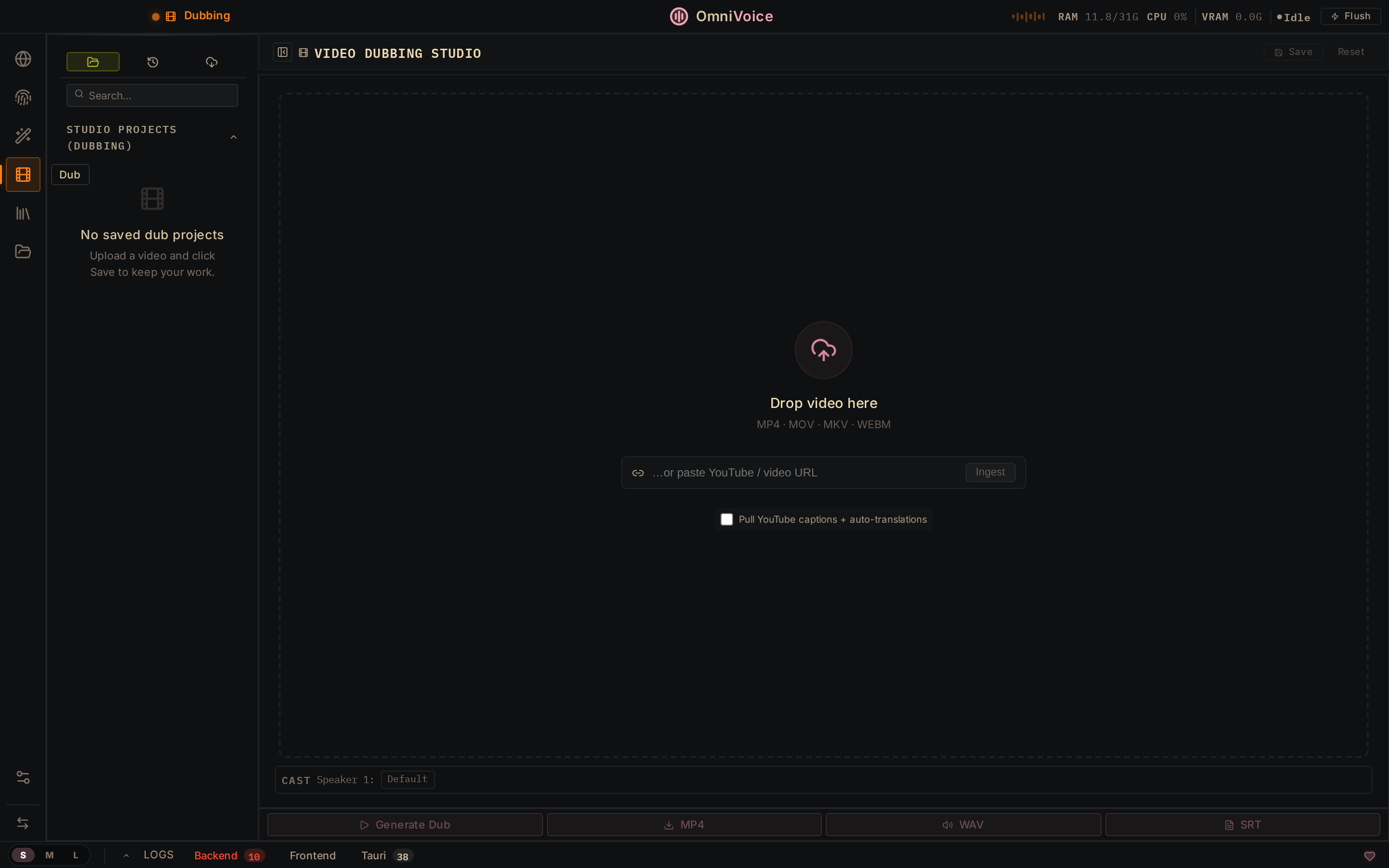
Video Dubbing Upload or paste a YouTube URL. Transcribe, translate, re-voice, export. |
Voice Gallery Search YouTube, browse categories, download clips, build your library. |
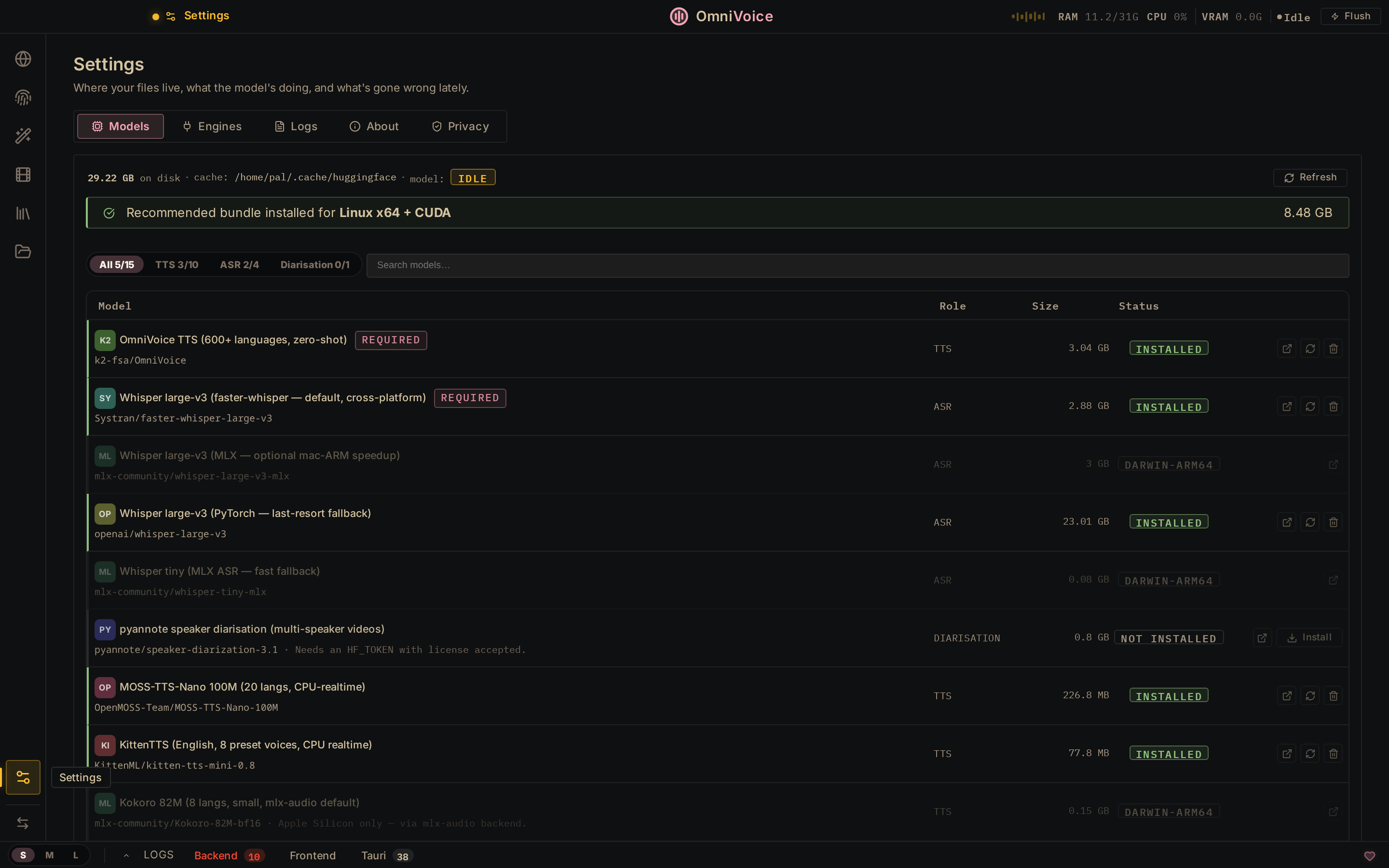
Settings → Models 15 models. One-click install. Auto-detects your platform (CUDA / MPS / CPU). |
Projects Dub projects, voice profiles, generation history, exports — all searchable. |
Settings → Logs Live backend, frontend, and Tauri runtime logs. Filter, refresh, clear. |
|
Why Open Source?
ElevenLabs charges $5–$330/mo and processes your audio on their servers. OmniVoice Studio runs on your hardware, with no usage limits.
| ElevenLabs | OmniVoice Studio | |
|---|---|---|
| Pricing | $5–$330/mo, per-character billing | Free for personal use · Commercial license for business |
| Voice Cloning | ✅ 3s clip | ✅ 3s clip, zero-shot |
| Voice Design | ✅ Gender, age | ✅ Gender, age, accent, pitch, style, dialect |
| Languages | 32 | 646 |
| Video Dubbing | ✅ Cloud-only | ✅ Fully local |
| Data Privacy | Audio sent to cloud | Nothing leaves your machine |
| API Keys | Required | Not needed |
| GPU Support | N/A (cloud) | CUDA · Apple Silicon · ROCm · CPU |
| Desktop App | ❌ | ✅ macOS · Windows · Linux |
| Customizable | ❌ Closed | ✅ Fork it, extend it, ship it |
Built on the OmniVoice 600-language zero-shot diffusion TTS model. Upload a video, get broadcast-quality dubs in any language with the original speaker's voice preserved.
Features
Core Pipeline
- Video Dubbing — Transcribe → translate → synthesize → mux back to MP4. One-click end-to-end.
- Vocal Isolation — Demucs-powered speech/music separation. Background audio preserved automatically.
- Voice Cloning — Clone any voice from a 3-second clip. Zero-shot, 600+ languages.
- Multi-Speaker Diarization — Pyannote + WhisperX fusion auto-identifies speakers and assigns unique voice profiles.
Studio Tools
- Voice Preview — Floating widget for instant 8-step TTS testing. Try voices without leaving the workspace.
- Multi-Language Batch — Select multiple target languages, dub to all in one pass.
- Batch Queue — Drag-and-drop bulk video processing with sequential GPU execution.
- Voice Library — Browse, favorite, tag, and convert gallery clips into permanent voice profiles.
- A/B Comparison — Side-by-side voice audition for casting decisions.
Production Export
- Selective Track Export — Choose which language tracks to include in the final MP4.
- Subtitle Export — SRT and VTT generation alongside dubbed video.
- Stem Export — Separate vocals and background audio as individual files.
- Per-Segment Mixing — 0–200% gain control per segment for broadcast-quality balancing.
Technical
- Cross-Platform GPU — Auto-detects CUDA, Apple Silicon (MPS), ROCm, or CPU. Includes automatic cuDNN 8/9 compatibility handling.
- VRAM-Aware — Automatically offloads TTS to CPU during transcription on ≤8 GB GPUs. Zero config.
- Live Telemetry — Real-time CPU/RAM/VRAM stats with model warm-up indicator.
- Keyboard-First —
⌘+Entergenerate,⌘+Ssave,⌘+Z/⌘+⇧+Zundo/redo.
AI Provenance
- Invisible Watermark — AudioSeal-powered (Meta) neural watermark embedded in every generated audio. Imperceptible, survives compression/editing.
- Detection API — Upload any audio to
/watermark/detectto verify OmniVoice origin with confidence score. - Video Branding — Optional logo overlay on exported MP4s (5s fade-out, bottom-right).
- Configurable — Toggle invisible/visible watermarks independently in Settings → Privacy.
Quickstart
Docker (recommended)
git clone https://github.com/debpalash/OmniVoice-Studio.git
cd OmniVoice-Studio
docker compose up --build -d
Open http://localhost:8000. GPU passthrough works automatically if nvidia-container-toolkit is installed.
Local Development
Prerequisites: ffmpeg, Bun, uv
git clone https://github.com/debpalash/OmniVoice-Studio.git
cd OmniVoice-Studio
bun install
bun run dev
This boots both services:
| Service | URL | Stack |
|---|---|---|
| Backend | localhost:3900 | FastAPI · 97 endpoints · WhisperX · Demucs · OmniVoice |
| Frontend | localhost:3901 | React · Vite · Waveform timeline · Glassmorphism UI |
[!NOTE] First run downloads model weights (~2.4 GB). This works out of the box — no account needed. For faster downloads, optionally set
HF_TOKEN=hf_...in your environment (get a free token here).Having issues? Join our Discord for setup help and troubleshooting.
Desktop App
bun run desktop # Launches Tauri native app (macOS / Windows / Linux)
System Requirements
| Minimum | Recommended | |
|---|---|---|
| OS | Windows 10, macOS 12+, Ubuntu 20.04+ | Any modern 64-bit OS |
| RAM | 8 GB | 16 GB+ |
| VRAM (GPU) | 4 GB (auto-offloads TTS to CPU) | 8 GB+ (NVIDIA RTX 3060+) |
| Disk | 10 GB free (models + cache) | 20 GB+ SSD |
| Python | 3.10+ (managed by uv) | 3.11–3.12 |
| GPU | Optional — CPU works | NVIDIA CUDA · Apple Silicon MPS · AMD ROCm |
[!TIP] On GPUs with ≤8 GB VRAM, OmniVoice automatically offloads TTS to CPU during transcription — no config needed. A dedicated GPU is not required; the entire pipeline runs on CPU (just slower).
Architecture
┌─────────────────────────────────────────────────┐
│ Frontend (React) │
│ DubTab · VoicePreview · BatchQueue · Gallery │
├─────────────────────────────────────────────────┤
│ Backend (FastAPI) │
│ 97 API endpoints · SSE streaming · SQLite │
├──────────┬──────────┬──────────┬────────────────┤
│ WhisperX │ Demucs │OmniVoice │ Pyannote │
│ ASR │ Source │ TTS │ Diarization │
│ │ Sep. │ │ │
└──────────┴──────────┴──────────┴────────────────┘
CUDA / MPS / ROCm / CPU (auto-detected)
Roadmap
✅ Shipped
| Category | Features |
|---|---|
| Dubbing | Full pipeline (transcribe→translate→synthesize→mux), scene-aware splitting, lip-sync scoring, streaming TTS |
| Voice | Zero-shot cloning, voice design, A/B comparison, voice preview widget, gallery with favorites/tags |
| Audio | Demucs vocal isolation, per-segment gain, selective track export, stem/SRT/VTT/MP3 export |
| Multi-Lang | Multi-language batch picker, batch dubbing queue with sequential GPU execution |
| Diarization | Pyannote ML diarization, auto speaker clone extraction, per-speaker voice assignment |
| Infra | Docker deployment, CUDA/MPS/ROCm auto-detect, cuDNN 8 compat, VRAM-aware model offloading |
| AI Provenance | AudioSeal invisible watermarking (SynthID-like), video logo overlay, watermark detection API |
| UX | Undo/redo, keyboard shortcuts, drag-and-drop, session persistence, glassmorphism design system |
🔜 Next — by priority
⚡ Performance (highest user-visible impact)
- Batched TTS (8–16 segments per forward pass) — 3–5× throughput
- Eliminate per-segment disk round-trips in
dub_generate.py - Cold start ≤ 1.5s (currently ~4s on Apple Silicon)
- Crash-sandbox GPU engines (subprocess isolation)
✨ Differentiators (what no competitor has)
- Real-time dub preview — stream TTS as you edit, no full re-render
- Project-level casting view — drag voices to speakers
- Context-aware pipeline — video frames inform dubbing decisions
- Voice memory across projects
🎨 Polish & Quality
- Accessibility audit — WCAG AA, ARIA live regions, full keyboard nav
- Waveform timeline v2 — WaveSurfer continuous regions overlay
- Onboarding sample clip — pre-loaded project for first-run experience
- Zustand migration — extract App.jsx (94KB, 41 useState calls)
📦 Productisation
- Signed Tauri installers + auto-update (macOS / Windows / Linux)
- Plugin SDK for third-party TTS engines (ElevenLabs, XTTS, Bark)
- LLM-powered translation (GPT/Claude for nuanced localization)
FAQ
Is this really as good as ElevenLabs?
For voice cloning and dubbing, yes — OmniVoice uses a state-of-the-art diffusion TTS model with 646 languages (ElevenLabs supports 32). Quality is comparable for most use cases. Where ElevenLabs wins is in their polished cloud API and pre-made voice library. OmniVoice wins on privacy, cost, language coverage, and customizability.
Does it work on Apple Silicon (M1/M2/M3/M4)?
Yes. MPS acceleration is auto-detected. MLX-optimized Whisper models are available for faster transcription on Apple hardware.
How much VRAM do I need?
4 GB minimum. With ≤8 GB, the TTS model is automatically offloaded to CPU during transcription. With 8+ GB, everything runs on GPU simultaneously. No GPU at all? CPU mode works — just slower (~3× for TTS).
Can I use this commercially?
Personal and non-commercial use is free. Commercial use requires a paid license — see License. 30-day free evaluation for businesses.
What languages are supported?
646 languages for TTS via the OmniVoice model. Transcription (WhisperX) supports 99 languages. Translation coverage depends on the target language pair.
Can I add my own TTS engine?
Not yet — a Plugin SDK is on the roadmap. The architecture is modular, so integration is straightforward for contributors.
License
Personal, educational, and non-commercial use — completely free. No restrictions, no limits.
Commercial use (SaaS, paid products, enterprise) — requires a paid license. 30-day free evaluation included.
See LICENSE for the full terms. For commercial inquiries, reach out at OmniVoice@palash.dev.
Contributing
Issues and PRs welcome. See the roadmap for areas where help is most needed. Join our Discord to discuss ideas, get help, or find what to work on.
Acknowledgments
OmniVoice Studio is built on the shoulders of exceptional open-source work:
| Project | Role |
|---|---|
| OmniVoice (k2-fsa) | Zero-shot diffusion TTS engine — the core voice synthesis model |
| WhisperX | Word-level speech recognition and alignment |
| Demucs (Meta) | Music source separation for vocal isolation |
| Pyannote | Speaker diarization — who said what |
| CTranslate2 | Optimized Transformer inference on CPU and GPU |
| AudioSeal (Meta) | Invisible neural audio watermarking for AI provenance |
| Tauri | Native desktop app framework |
⭐ Star on GitHub to follow updates.